फक्त चार / पाच ओळींचा कोड लिहून आपण मराठी भाषेतील संबंधित तसेच विरुद्धार्थी शब्द शोधू शकतो. उदाहरण म्हणून मी "संगीत" हा शब्द दिल्यावर मॉडेलने "कला" , "कविता", "नाटक" , "महाराष्टर", " "भारत" असे शब्द दिले.
https://ic.pics.livejournal.com/shantanuo/56336/1952/1952_900.png
{kind=link}
आता यात काय मोठे दिवे लावले? असा प्रश्न साहजिकच आहे. तसेच संगीताचा युद्धाशी आणि कंपनीशी कसा संबंध ते स्पष्ट करा असा उपरोधही अपेक्षित आहे. त्याचे उत्तरः
१) हे मॉडेल विकिपीडियावरून फार पूर्वी बनवलेले आहे. २०१३ साली मराठी विकिपीडियावर फारसे लेख नव्हते. जसा डेटा वाढत जाईल तशी क्वालिटी वाढेल. गुगल न्यूजचा डेटा वापरून वापरून बनवलेले (इंग्लिश) मॉडेल प्रसिद्ध आहे. मराठीला तेवढी उंची गाठायला वेळ लागेल. पण निदान शक्यता वाटू लागली आहे.
२) अनेकदा आवाहन करूनही मराठीसाठी काही करू शकणारे स्वयंसेवक मिळत नाहीत. ज्यांना वेळ आहे त्यांना संगणक हाताळता येत नाही. तर संगणक तत्ज्ञांना अशा कामासाठी वेळ नाही. मशीन लर्निंगच्या माध्यमातून भविष्यात मोठमोठे कोशदेखील सिद्ध होतील. असे कोश १००% अचूक नसतील हे मान्य. पण त्यातून कामाची निकड भागेल. हे महत्त्वाचे .
या क्षेत्राचे भवितव्य उज्ज्वल आहे. मराठीच नव्हे तर सर्व तरुणांनी यात लक्ष घालायला हवे.
{kind=link}
## download the pre-trained
## download the pre-trained model:
wget http://bit.ly/12FI1xV
mv 12FI1xV polyglot-mt.pkl
## install python 2.7 package
pip install polyglot
## run this code to get the output shown as in the image
## https://ic.pics.livejournal.com/shantanuo/56336/1952/1952_900.png
import polyglot
from polyglot.mapping import Embedding
embeddings=Embedding.load("polyglot-mt.pkl")
neighbors = embeddings.nearest_neighbors("संगीत")
for i in neighbors:
print (i.encode('utf-8'))
शन्का:
aataa samajalaa nemkaa kaay mhanayach aahe tumhala te.. thanks
शन्का:
१. polyglot वापरुन text similarity analysis (between phrases) करता येत का?
semantic text similarity साठी gensim वापरल आहे ह्य अधी
'२. wget च्या use cases काय आहेत,
it is pre trained model for predictive analysis, right?
polyglot वापरुन text
polyglot वापरुन text similarity analysis (between phrases) करता येत का?
Yes. That is possible.
semantic text similarity साठी gensim वापरल आहे ह्य अधी
gensim is similar to this.
wget च्या use cases काय आहेत,
wget is used to download a file directly from net to linux local disk.
it is pre trained model for predictive analysis, right?
Yes right.
Please email me directly at shantanu.oak@gmail.com instead of writing a comment on maayboli.
Please email me directly at ?
Please email me directly at ?? ओके... सविस्तर बोलुच मेल वर. आधी ती लिन्क बघ्ते काय आहे ते
The advantage of polyglot is
The advantage of polyglot is that it also support transliteration (Not translation)
from polyglot.transliteration import Transliterator
transliterator = Transliterator(source_lang="en", target_lang="mr")
your_text='shntnoo prbhakar'
for i in your_text.split():
print(transliterator.transliterate(i))
This will return शंतनू प्रभाकर in unicode!
The advantage of polyglot is
The advantage of polyglot is that it also support transliteration>> भारी
I am aware of transliteration tools, I am its end user since "stone age"
text similarity analysis मध्ये सध्या जास्त डोक लावत आहे , need a model/algo/package with good accuracy
मशीन लर्निंग वापरून इंग्रजीचे
मशीन लर्निंग वापरून इंग्रजीचे मराठी भाषांतर कसे करता येऊ शकेल ते येथे वाचता येईल.
https://towardsdatascience.com/word-level-english-to-marathi-neural-mach...
मूळ इंग्रजी वाक्य: you cant speak french can you
भाषांतर केलेले मराठीः तुला फ्रेंच बोलता येत नाही का नाही माहीत
गुगलने शोधलेले tensorflow आणि ओपन सोर्स मधील "केरास” आणखी काय काय चमत्कार करतात ते पाहणे मनोरंजक ठरणार आहे.
मशीन लर्निंग हे प्रकरण काय
मशीन लर्निंग हे प्रकरण काय आहे आणि ते कसे शिकू शकते याचे एक चांगले उदाहरण म्हणजे जेनसिम (jensim) या मॉड्यूलमधील उदाहरण पाहू.
king - man+ woman = ?
याचे उत्तर २०१२ साली कॉम्युटरने "queen” असे अचूक दिले आणि "लडका हुवा जवा रे" असा अनेकांना साक्षात्कार झाला. कारण किंग म्हणजे राजा, त्यातून पुरूष वजा करून त्याचे स्त्रीलिंगी रुप शोधणे ही आपल्या दृष्टीने शाळकरी पण विज्ञानाच्या दृष्टीने क्रांतिकारी घटना ठरली. एखादे यंत्र शब्द त्यांच्या अर्थासहित समजू शकते हे लक्षात आल्यावर अनेक दारे आपोआप उघडली गेली. त्यातील एक दार होते फोटोंचे. शब्दांची बेरीज वजाबाकी होऊ शकते तशी फोटोची होऊ शकते. उदाहरण म्हणून आपण ट्रंप यांच्या फोटोची बेरीज त्यांच्या आवडत्या भिंतीच्या फोटोशी करून नवीन फोटो तयार करू शकतो.
दुसरे उदाहरण म्हणजे शि. द. फडणीस या प्रसिद्ध व्यंगचित्रकाराच्या एखाद्या फोटोतील रंगसंगती दुसर्या एखाद्या फोटोला देऊन तो फोटो त्यांनीच रंगवलेला आहे असा आभास निर्माण करणे शक्य आहे.
चाळीस, पन्नास वर्षांपूर्वीचे कृष्णधवल फोटो रंगीत करणे म्हणजे "किस झाड की पत्ती". उदाहरण म्हणून माझे लहानपणीचे फोटो रंगीत केले!
आपल्या मोबाईलवर एखाद्या कुत्र्याचा फोटो घेऊन तो नेमका कोणत्या जातीचा आहे हे सांगणारी मोबाईल ऍप प्ले स्टोरवर उपलब्ध आहेत.
https://play.google.com/store/apps/details?id=com.siwalusoftware.dogscanner
यातही मशिन लर्नींग ऑलगोरिदम वापरले गेले आहे. आपण खेळत असलेल्या अनेक मोबाईल गेममध्ये ML / DL /AI (Artificial Intelligence) आहेच. अॅमेझॉन / गुगल सारखी संकेतस्थळे मोठ्या प्रमाणावर या तंत्राचा उपयोग करीत आहेत.
पायथॉनचे प्राथमिक ज्ञान असलेला कोणीही हे करू शकतो. खाली दिलेल्या लिंकवर त्याचा कोड उपलब्ध आहे.
https://github.com/RaRe-Technologies/gensim
https://github.com/lengstrom/fast-style-transfer
https://github.com/jantic/DeOldify
https://github.com/jamesrequa/Dog-Breed-Classifier/blob/master/dog_class...
_____
नवीन तंत्रज्ञानाचा उपयोग लक्षात येण्याअगोदर त्याचा दुरुपयोग सुरू होतो.
मशीन लर्निंग / डिप लर्निंग त्याला अपवाद नाही. उदाहरण म्हणून deepfake तंत्र वापरून अश्लिल चित्र निर्मिती कधीच सुरू झाली आहे.
https://en.wikipedia.org/wiki/Deepfake
“facial recognition banned” असे गूगलमध्ये शोधल्यास अमेरिकेतील अनेक लोक फेस रिकग्निशनच्या विरोधात का आहेत ते समजू शकते.
गुन्हेगारी प्रवृत्तीचे लोक भविष्यात त्याचा अधिक कल्पक वापर करण्याची शक्यता आहे. त्याला इलाज नाही.
छान पोस्ट शंतनू जी,
छान पोस्ट शंतनू जी, उदाहरणांनी मजा आली वाचताना
Image search विषयी वाचायला
Image search विषयी वाचायला आवडेल
ओपन एआय या संस्थेने जी-पी-टी
ओपन एआय या संस्थेने जी-पी-टी-२ हे मॉडेल बाजारात दाखल केले आहे.
https://openai.com/blog/better-language-models/
काल्पनिक बातम्या तयार करणे, धडा वाचून धड्याखालील प्रश्नांची उत्तरे देणे असे तद्दन शाळकरी चाळे संगणकाला जमू लागले यात इतका हर्षवायू होण्यासारखे काय आहे असा प्रश्न एखाद्याला पडू शकतो. पण याचा अर्थ आता संगणकाला नुसते शब्द नव्हे तर शब्दामागचा अर्थही कळू लागला आहे व त्याचे पुढचे शिक्षण कल्पनातीत वेगाने होईल या नुसत्या शक्यतेने जगातील विचारवंत हैराण आहेत.
छान माहिती दिलीत शंतनू जी!
छान माहिती दिलीत शंतनू जी!
Opencv (OpenCV: Open source
Opencv (OpenCV: Open source computer vision library) चा वापर करून Character recognition, Face detection, eyes, pupil, nose detection and tracking उत्तमरीत्या करता येते. अनेक libraries available आहेत. त्यापैकी Haarcascade ही library मी use केली आहे. Perfectly काम करते. Bounding boxes create होतात. OpenCV हे C++, Python, Java etc. मध्ये use करू शकतो.
फेसबुकने मराठीसह १५0 पेक्षा
फेसबुकने मराठीसह १५0 पेक्षा जास्त भाषांचे प्री-ट्रेन्ड मॉडेल सुमारे एका वर्षापूर्वी उपलब्ध करून दिले आहे. यात कंपनीने स्वार्थ आणि परमार्थ दोन्ही साधला आहे. फेसबुकचे या बाबतीत अभिनंदन केले पाहिजे.
https://fasttext.cc/docs/en/crawl-vectors.html
पायथॉनची ही स्क्रिप्ट वापरून मी हे मॉडेल वापरून पाहिले.
"प्रचंड" या शब्दाचे समानार्थी शब्द अगदी अचूक मिळत आहेत हे पाहून मी आधी प्रचंड प्रभावित झालो.
print_most_similar(words, 'प्रचंड')
खूप, अफाट, अपरिमित, अतोनात, अतिशय, फार, जबरदस्त, प्रमाणात, भयंकर, भरपूर
इतकेच नव्हे तर "तिच्या" - “तिला" या शब्दांचा एकमेकांशी असलेला संबंध लक्षात घेऊन "माझ्या" शब्दाला "मला" हा शब्द सुचविला जात आहे. हे मोठे यश म्हणावे लागेल.
print_analogy('तिच्या', 'तिला' , 'माझ्या', words)
तिच्या-तिला is like माझ्या-मला
हे यश फक्त काही ठरावीक शब्दांपुरतेच मर्यादित दिसते. कारण इतर शब्दांना अगदी असंबद्ध प्रतिसाद मिळतो तर काही शब्दच डेटाबेसमध्ये नसल्याचा संदेश येतो. अर्थात यात फेसबुकची चूक नाही. कारण हे मॉडेल विकिपीडियावर आधारलेले आहे. आडातच नाही तर पोहऱ्यात काय येणार?
मशीन लर्निंगचे हे मॉडेल जर अधिक प्रभावी करायचे असेल तर विकिपीडिया लेखन व पायथॉन जाणकारांनी या मॉडेलचा अधिकाधिक कल्पक वापर हे दोन उपाय आहेत.
छान उदाहरणे आणि चर्चा.
छान उदाहरणे आणि चर्चा.
उपयुक्त आणि ज्ञानात मोलाची भर
उपयुक्त आणि ज्ञानात मोलाची भर घालणारी चर्चा. shantanuo खूप खूप धन्यवाद. यथावकाश मी सुद्धा लिहीन इथे.
काही दिवसांनी आन्सरींग मशीन
काही दिवसांनी आन्सरींग मशीन कॉल करणाऱ्या व्यक्तींना आपल्या आधीच्या संभाषणाचे योग्य व त्वरीत विश्लेषण करून त्या त्या व्यक्तीला योग्य असे उत्तर/निरोप देऊ शकेल. तसेच वाणसामान व इतर वस्तू गरजेनुसार ऑर्डर देऊन परस्पर मागवून घेणारे केअरटेकर संगणक/ रोबो घरोघरी आढळतील.
लोकेश शेवडे यांचा
लोकेश शेवडे यांचा लोकसत्ताच्या (३१ मे) लोकरंग पुरवणीतील लेख आवर्जून वाचण्यासारखा आहे.
https://www.loksatta.com/lokrang-news/increasing-number-of-singers-on-so...
त्याचा गोशवारा साधारण असा आहे….
त्या अत्यंत प्रगत तंत्रज्ञानानं ‘कलावंतां’च्या अभ्यासाला, रियाझाला आणि कार्यक्रमांना वाव मिळेल, क्षेत्र वृद्धिंगत होईल, इथपर्यंतच माझी बुद्धी पोहोचली होती. पण ज्यांचा गायनाशी, सुरांशी, संगीताशी, रियाझाशी किंवा अभ्यासाशी दूरान्वयेही संबंध नाही; किंबहुना जे या साऱ्या प्रकारांचे शत्रू आहेत, त्या ‘असुरां’च्याही हाती हे ‘अॅप’ येईल आणि त्यातून ते ‘भेसूर’ता फैलावतील आणि त्यांच्या समसुखी असुरांकडून वाहवाही मिळवतील हे माझ्या लक्षातच आलं नव्हतं. साधनं ‘मुबलक होणं, सुलभतेनं ती प्राप्य होणं’ याचा अर्थ ती साधनं बहुसंख्य असलेल्या ‘असुरां’नाही प्राप्य होणं, हे उरलेलं अर्धसत्य माझ्या मित्रानं पाठवलेल्या या क्लिपमुळे मला उलगडलं. कराओके, फोटो मॉर्फिगसारखे असत्यावर सत्याची झूल ‘बेमालूम’पणे पांघरण्याचे ‘अॅप्स’ जेव्हापासून ‘फ्री डाऊनलोड’ झाले तेव्हापासून बहुसंख्याकांना सत्य, ज्ञान आणि अस्सलतेला चिरडणं अगदी सोपं झालं आहे.
त्यांनी त्यांची व्यथा अगदी नेमक्या शब्दात मांडली आहे खरी पण बहुसंख्याकांना असुर म्हणणं थोडं जास्तच होत आहे असे मला वाटते. कारण हे "सो कॉल्ड" असुर आपल्या आजूबाजूला वावरत असतात, आपण सर्वच त्या असुरसंप्रदायाचे पाईक आहोत.
त्याच बरोबर बहुसंख्याक मंडळींवर ते सत्य, ज्ञान आणि अस्सलतेला बुटाखाली घेऊन चिरडत आहेत असा आरोप करणे साफ चूक आहे. कारण ज्यांना मुळात सत्य, ज्ञान आणि अस्सलता म्हणजे काय हेच माहीत नाही ते त्याला काय आणि कसे चिरडणार? मुंबईची गर्दी काही वेळा अनावर होते त्याला इंग्रजीत स्टेंपेड (stampede) की काय असंच काहीसं म्हणतात. अशा वेळेला पायाखाली जे येतं ते सारंच तुडवलं जातं, त्यात काही भेदभाव नसतो.
मशीन लर्निंग, आर्टिफिशियल इंटेलिजन्स या व अशा भारी तंत्रज्ञानाने गरीब / श्रीमंत हा भेद बुजवला, देशाच्या सीमा बुजवल्या हे खरे. पण त्याचबरोबर सत्य - असत्य यातील सीमारेषादेखील कधी नव्हे इतकी धूसर केली आहे. पूर्वी लोकांना "किक” येण्याकरता दारू, सिग्रेट, अमली पदार्थ लागत आता त्याची जागा मोबाईल फोनने घेतली आहे. त्याचा अंमल चढला की आपल्याला आनंद होत आहे की वेदना होत आहेत हे देखील माणसाला खात्रीने सांगता येत नाही. अशा वेळेला कुठूनतरी आलेलं पोस्ट वॉट्सॅपवर फॉरवर्ड करण्यापलीकडे तो तरी काय करणार? माणसाच्या बहुतेक सर्व समस्यांच्या मुळाशी अज्ञान नव्हे तर अगतिकता आणि असहायता असते. तंत्रज्ञानाने ही अगतिकता कमी करावी अशी अपेक्षा आहे. ही अपेक्षा पुरी होत आहे की नाही ते येणारा काळ ठरवेल.
मशीन लर्निंग, आर्टिफिशियल
मशीन लर्निंग, आर्टिफिशियल इंटेलिजन्स म्हणजे अलिबाबाची गुहाच. जेवढे वाचावे तेवढे डोळे मोठे होत जातात. साध फोर्ट्रान किंवा बेसिक प्रोग्रमिंग माहित असलेल्या मला पुढे कसे शिकता येइल?
छान आहे माहिती.
छान आहे माहिती.
जीमेल मध्ये टाईप करताना
जीमेल मध्ये टाईप करताना आपल्याला स्पेल चेक वापरता येतो हे तर सर्वांना माहीत आहे. पण आता संदर्भ लक्षात घेऊन सुधारणा सुचविली जात आहे. म्हणजे मी "But when I added a new version, it fails. ” असे टाईप केले की added शब्दाखाली निळी रेघ येते (लाल नव्हे!) आणि add अशी सुचवणी येते. वास्तविक added आणि add दोन्ही शब्द शुद्धच आहेत. पण कोणता शब्द कुठे, कधी वापरावा हे संदर्भाने ठरते आणि ते देखील संगणकाला समजू शकते.
आपला मोबाईल फोन गेल्या दहा वर्षात जसा "स्मार्ट” झाला, तसाच स्पेल चेक देखील अधिक कार्यक्षम झालेला दिसतो. इंग्रजी व्यतिरिक्त इतर भाषांमध्ये असे संदर्भासहित शुद्धिकरण शक्य आहे असे ह्या पेपरचे म्हणणे आहे.
https://arxiv.org/pdf/1910.11242.pdf
मला फक्त न्यूज पेपर वाचायची सवय आहे त्यामुळे हा पेपर समजायला थोडा कठीण गेला. पण इथल्या कुणाला तरी मराठीत असा स्मार्ट स्पेल चेकर कसा आणता येईल ते शोधता येईल. म्हणजे बघा. “मी शाळेत जातो.” या वाक्यातील तिन्ही शब्द शुद्ध आहेत. बरोबर? पण ह्या वाक्यात?
ती म्हणाली, “मी शाळेत जातो.”
इथे "जातो” नव्हे तर "जाते” अपेक्षित आहे. अशी सुधारणा फक्त मशीन लर्निंग आणि आर्टिफिशियल इंटलिजंस या दोन मार्गांनीच शक्य आहे. ज्यांना या विषयात गती आहे त्यांनी लक्ष घातले तर भाषेला या तंत्रज्ञानाचा प्रचंड फायदा होईल.
हगिंग फेस या कंपनीने भाषांतर
"हगिंग फेस" या कंपनीने भाषांतर करण्यासाठी अनेक मॉडेल उपलब्ध करून दिली आहेत. इंग्रजीतून मराठीत भाषांतर येथे पाहता येईल.
https://huggingface.co/Helsinki-NLP/opus-mt-en-mr
गुगलच्या तुलनेत हा प्रयत्न हास्यास्पद आहे हे खरे. पण फ्री आणि ओपन सोर्स या लायसन्सखालील कोणताही प्रयोग मला महत्त्वाचा वाटतो म्हणून नोंद घेतली.
मराठी विकिपीडियाचा डेटाबेस
मराठी विकिपीडियाचा डेटाबेस वापरून मशिन लर्निंगचे मॉडेल बनवून वापरून पाहिले आणि अपेक्षेप्रमाणे अपेक्षाभंग झाला. कोणाला वापरून खात्री करून घ्यायची असेल तर पायथॉन कोड खाली दिला आहे.
https://github.com/shantanuo/spell_check/blob/master/ml_marathi_spell_ch...
पहिल्या उदाहरणात 'अपेषित' या शब्दाला 'अपेक्षित' तर 'मजकर' ला 'मजकूर' अशी सुचवणी आलेली असली तरी त्यात हुरळून जाण्यासारखे काही नाही. कारण ते वाक्य विकिपीडियामधील आहे, म्हणजेच मॉडेलने ट्रेन होताना ते पाहिले आहे. हे ओव्हरफिट मॉडेल आहे. विकिपीडियामधील मजकूर कदाचित स्पेल चेक करील पण नवीन मजकूर नीट चेक करू शकणार नाही. हे दुसऱ्या उदाहरणात लगेच दिसते. "कधी राहाला येणेही" यात "राहायला" अपेक्षित होते तर सुधारणा झाली ती "राहिला” अशी. तर "आवत” शब्द तसाच राहिला. त्याचा "आवडत” झाला नाही. मुळात स्पेलचेकचे मॉडेल बनविण्यासाठी विकिचा वापर करणे म्हणजे मोर नाचतो म्हणून लांडोर नाचते तसा प्रकार झाला. इंग्रजी विकी म्हणजे अक्षरशः समुद्र आहे. मराठी विकी त्यामानाने नदी सुद्धा म्हणता येणार नाही. आकाराचा फरक सोडला तरी लिपीचा आणि भाषेचा फरकही आहे. त्यातील २, ३ मुद्दे असे...
१) अशुद्ध लेखन – नवीन लेखकांना कमीत कमी त्रासात लेखन करता यावे याला विकिपीडियाने प्राधान्य दिल्यामुळे शुद्धलेखन पूर्णपणे बादच झाल्यासारखी स्थिती आहे.
२) विशेषनामे - नावे - आडनावे उदा. आवतारकर वगैरे
३) हिंदी शब्द – संदर्भासाठी हिंदीचा काही प्रमाणात वापर झाला आहे. उदा.
त्यांच्या 'जमुना के तीर', 'गोपाला करुणा क्यूं नही आवे', 'पिया के मिलन की आस', 'नैना रसीले', 'पिया बीन नही आवत चैन' यांसारख्या अजरामर ध्वनिमुद्रणांनी आजही ते रसिकांच्या हृदयात घर करून आहेत.
इंग्रजी/ गुजराती मजकूर लिपीचा आधार घेऊन काढला पण हे शब्द काढण्याची कोणतीही सोय नाही. मॉडलने ते प्रमाण भाषेतील शब्द आहेत असे गृहीत धरले आहे.
युनिकोडमधील खूप मोठा डेटा ओपन सोर्स लायसंसखाली उपलब्ध झाला तर कदाचित असा प्रयत्न यशस्वी होऊ शकेल. पण तशी शक्यता फार कमी आहे.
"महागाई वाडते" असे लिहिल्यावर
"महागाई वाडते" असे लिहिल्यावर अपेक्षेप्रमाणे वाडते शब्दाखाली लाल रेघ येते. पण पर्यायात मात्र "नावडते, वाडगे, डावलते, वावडे” असे चार शब्द दिसतात. येथे निखालसपणे "वाढते” हाच शब्द बरोबर असूनही तो पर्यायात दिसत नाही. हंस्पेल संदर्भ अजिबात लक्षात न घेता शब्द सुचवितो हा एक खूप मोठा तोटा आहे. मशिन लर्निंग यात काही प्रमाणात उपयोगी होऊ शकते. मराठी बायग्रॅमची फाइल येथून डाऊनलोड करू शकता.
wget https://kagapa.s3.ap-south-1.amazonaws.com/ml/marathi_bigram_count.txt.gz
gunzip marathi_bigram_count.txt.gz
बायग्रॅम म्हणजे शब्दांच्या जोड्या. “महागाई वाढत चालली आहे” याचा बायग्रॅम म्हणजे "महागाई वाढत”, “वाढत चालली”, “चालली आहे” गुगलने इंग्रजीतील ३१ कोटी शब्दजोड्या १५ वर्षांपूर्वीच उपलब्ध करून दिल्या आहेत.
https://ai.googleblog.com/2006/08/all-our-n-gram-are-belong-to-you.html
मराठीच्या या फाईलमध्ये ४२ लाख शब्दजोड्या उपलब्ध आहेत. यासाठी मराठी विकीचा डाटा वापरला आहे. याचा उपयोग लेखकाला पुढचा शब्द सुचविण्यासाठी देखील होऊ शकतो. उदाहरणार्थ मी जर "महागाई" हा शब्द टाईप केला तर पुढचा शब्द कोणता असेल? बायग्रॅम डेटामध्ये पाहिले की "वाढत”, "वाढली” किंवा "भत्ता” असा शब्द सुचविता येतील.
# grep '^महागाई' marathi_bigram_count.txt | sort -rk 3,3 | head
महागाई वाढत 6
महागाई वाढली 5
महागाई वाढण्याची 5
महागाईचा दर 4
महागाई भत्त्याची 4
महागाई झाली 4
महागाई कमी 4
महागाई आणि 4
महागाईच्या दिवसांत 3
महागाई वाढते 3
लोकसत्तामधील भाषेच्या
लोकसत्तामधील भाषेच्या अभ्यासाबद्दल एक लेख वाचनात आला.
https://www.loksatta.com/viva-news/viva-article-sociolinguistics-the-swe...
यात म्हटले आहेः
कुठल्याही भाषेच्या व्याकरणात विविध विभक्ती आणि त्यांचे प्रत्यय असतात आणि त्या त्या विभक्तीचं नेमून दिलेलं कार्य असतं आणि काही नवीन कार्य वापरानुसार नव्याने येतं. उदाहरणार्थ- ‘मी त्याला पुस्तक दिलं’ या वाक्यात ‘तो’ हा पुस्तक मिळणारा आहे. किंवा ‘त्याला थंडी वाजते आहे’. या वाक्यात ‘तो’ हा थंडी अनुभवणारा आहे. याव्यतिरिक्त आणखी काही माहिती हाती लागेल हे मी बघते आहे. उदाहरणार्थ- ‘तो अभ्यासाला बसला’. इथे कारण कळतं की ‘तो अभ्यासाला बसला आहे’. किंवा ‘मी पुण्याला गेले’ या वाक्यात ‘पुणे’ हे ‘गोल किंवा एण्ड पॉइंट’ आहे ही माहिती कळते. किंवा ‘तो पुण्याला शिकतो’ यात ‘तो’ पुण्यात एका महाविद्यालयात शिकतो हे कळतं. ‘ला’, ‘च्या’ अशा वाक्यांत वापरल्या जाणाऱ्या चतुर्थी विभक्ती प्रत्ययांच्या वेगवेगळ्या कार्यांचा अभ्यास मी करते आहे, असं ती सांगते.
_____
अशा अभ्यासासाठी देखील वर दिलेली बायग्रॅम फाईल उपयोगी ठरू शकते.
उदाहरणार्थः हे काही (च्या काही) निष्कर्षः
१) एकवचनी पुल्लिंगी शब्दांचा वापर स्त्रीलिंगी शब्दापेक्षा सुमारे दुप्पट आहे. (त्याला / तिला) पुरुषप्रधान संस्कृतीत हे अपेक्षितच आहे. पण अनपेक्षित काही असेल तर बहुवचनी स्त्रीलिंगी शब्दांचा वापर पुल्लिंगी शब्दांपेक्षा तिपटीने जास्त आहे (स्त्रियांना / पुरुषांना)
२) चतुर्थी प्रत्ययाचा वापर दिशा, गावे, व्यक्ती यांच्या बाबतीत जास्त दिसून येतो. (उत्तरेस, पुण्यास, माणसास)
cat marathi_bigram_count.txt | tr -s ' ' '\n' | grep 'स$' | sort | uniq -c | sort -bnr | more
819 उत्तरेस
795 दक्षिणेस
705 पुण्यास
611 पश्चिमेस
607 कामास
592 माणसास
536 राजास
528 मुलांस
523 मुलास
485 नजरेस
453 तुम्हांस
434 तुम्हास
429 वाचकांस
420 अनुभवास
406 एकमेकांस
393 मुंबईस
391 जन्मास
381 वाढीस
'स$' बदलून 'ला$' ने संपणारे शब्द शोधले.
13809 त्याला
11479 मला
7240 तिला
5654 आपला
4809 आपल्याला
4093 तुला
3654 याला
2393 तुम्हाला
2248 ज्याला
2199 बाजूला
1534 माणसाला
1444 स्वतःला
1318 सुरुवातीला
1294 मनाला
1232 कोणाला
अनेकवचनी "ना$” ने संपणारे शब्दः
15891 त्यांना
3906 लोकांना
2079 मुलांना
1257 विद्यार्थ्यांना
1213 शेतकऱ्यांना
1029 स्त्रियांना
800 मुलींना
795 ह्यांना
769 इतरांना
757 वाचकांना
748 सदस्यांना
355 पुरुषांना
अर्थात हा शब्दसंग्रह विकिपीडियावर आधारित असल्यामुळे त्यातील बायस यात झिरपले असण्याची शक्यता आहे!
खाली दिलेल्या तीन चुकीच्या
खाली दिलेल्या तीन चुकीच्या शब्दांच्या बाबतीत हंस्पेलने जे शब्द सुचविले आहेत त्यात अपेक्षित शब्द अनुक्रमे दुसऱ्या, तिसऱ्या आणि चौथ्या क्रमांकावर आहे.
करु ['करी', 'करू', 'करो', 'कर्क'],
करुन ['करुणा', 'करुया', 'करून', 'करेन'],
विषरला ['विषयाला', 'विषादला', 'विहरला', 'विसरला'],
वर दिलेली बायग्रॅम फाईल वापरली की अपेक्षित शब्द पहिल्या स्थानावर येत आहेत. याचे प्रात्यक्षिक खाली दिलेल्या पानावर पाहू शकता. अर्थात हंस्पेलमधील ट्राय आणि रिप्लेसमेंट टॅग वापरून देखील हे शक्य आहे. पण या शब्दजोड्यांमुळे हंस्पेलला संदर्भ लक्षात आणून द्यायचे काम होत आहे, जे मला महत्त्वाचे वाटले.
http://shantanuoak.com:5000/
कोणत्याही पानाचा ऍड्रेस यात टाकला की चुकीचा शब्द आणि त्यापुढे अपेक्षित शब्द दिसेल. हवे तर हेच पान स्पेल चेक करून पाहू शकता. हंस्पेल डिक्शनरीतील सर्व शब्दांना योग्य तो टॅग लावण्याचे काम पूर्ण झाले की हा स्पेल चेकर अधिक चांगल्या तऱ्हेने काम करेल.
कित्येकदा नकारात्मक
कित्येकदा नकारात्मक प्रतिक्रिया मायबोलीसारख्या संकेतस्थळावर दिसून येतात. काही वेळा तर द्वेषपूर्ण भाषाही वापरलेली दिसून येते. लेखक मात्र आपण फक्त आपले मत व्यक्त केले असे म्हणून मोकळा होतो. आता त्याच्या लेखनात किती जहर भरलेला आहे हे मोजण्याचे प्रमाण कुठे उपलब्ध आहे का? असा धारवाडी काटा मशीन लर्निंगच्या मॉडेलद्वारे उपलब्ध केला गेला आहे. उदाहरण म्हणून "मराठी सेंटीमेंट" या मॉडेलचा निष्कर्ष या चित्रात पाहू शकता किंवा खाली दिलेल्या वेबसाईटवर जाऊन कॉपी पेस्ट करू शकता.
https://huggingface.co/l3cube-pune/MarathiSentiment
हे मॉडेल उपलब्ध करून दिल्याबद्दल रविराज जोशी यांचे जेवढे आभार मानावेत तितके कमीच आहेत. एखादी प्रतिक्रिया ९९ टक्के "हेट स्पीच" या निकषात बसत असेल तर ती प्रतिक्रिया संपादकीय गाळणीतून जायला हवी. एखादे लेखन फारच जहाल झाले असेल तर ते नेमके किती स्फोटक आहे हे सांगणारे त्यांचे “hate-bert-hasoc-marathi” नावाचे मॉडेल देखील ऑनलाईन उपलब्ध आहे. अशा मॉडेलचे बरेच फायदे आहेत. उदाहरणार्थ बदनामी खटल्यात किंवा हिंसा भडकवण्याच्या आरोपात याचा पुरावा म्हणून उपयोग होऊ शकतो.
कैच्या काय.
कैच्या काय.
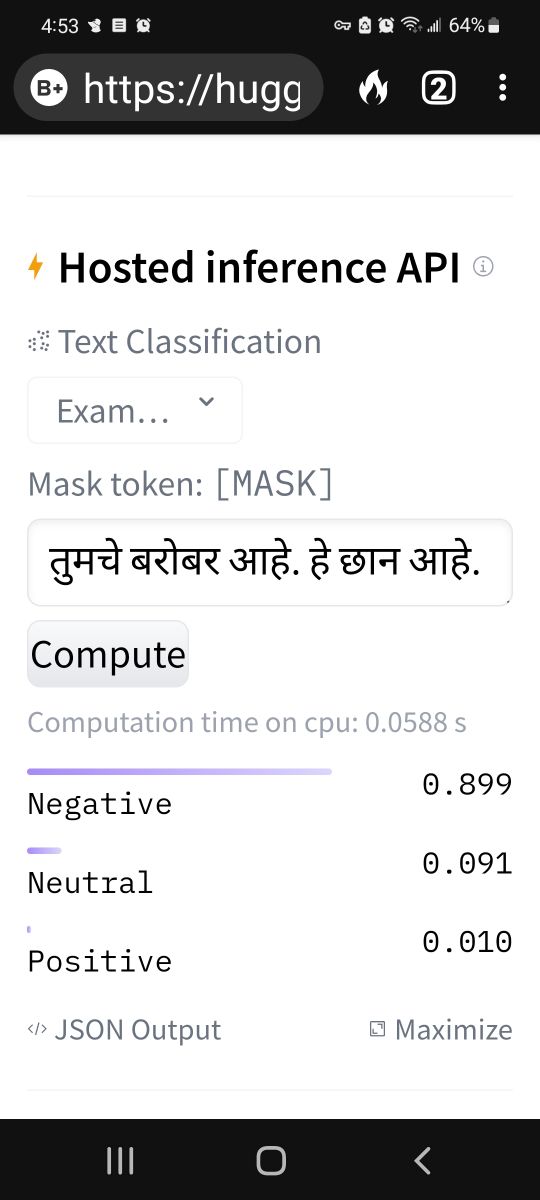
आता यात निगेटिव्ह काय आहे?
दोन पोसिटीव्हज मिळून एक
दोन पोसिटीव्हज मिळून एक निगेटिव्ह झाला असावा.
दर्शन देशपांडे यांनी
दर्शन देशपांडे यांनी "गाळलेल्या जागा भरा" छापाचे मॉडेल विकसित केले आहे.
https://huggingface.co/DarshanDeshpande/marathi-distilbert
उदाहरणार्थ
ग्रामपंचायतीच्या प्रमुखाला [MASK] म्हणतात
असे मी विचारल्यावर "सरपंच” असे उत्तर आले. तुम्ही विचारलेल्या प्रश्नाचे तुम्हाला अपेक्षित उत्तर कदाचित मिळणार नाही. याची अनेक कारणे आहेत. मॉडेल ट्रेन करण्याकरता कोणता डेटाबेस वापरला होता आणि मॉडेल बनविताना कोणता मसाला (ट्युनिंग पॅरॅमिटर) वापरला होता ते पहावे लागते. त्यांनी सुरुवात तर करून दिली आहे, यापेक्षा चांगले मॉडेल कोणी बनविले तर त्याचे स्वागतच आहे!
Pages